data-pipeline
This repository contains a set of marimo notebooks to streamline the data processing pipeline from raw IFCB images to CNN-classified datasets, with additional tools to set up PIVOT for validation. The pipeline steps are shown below:
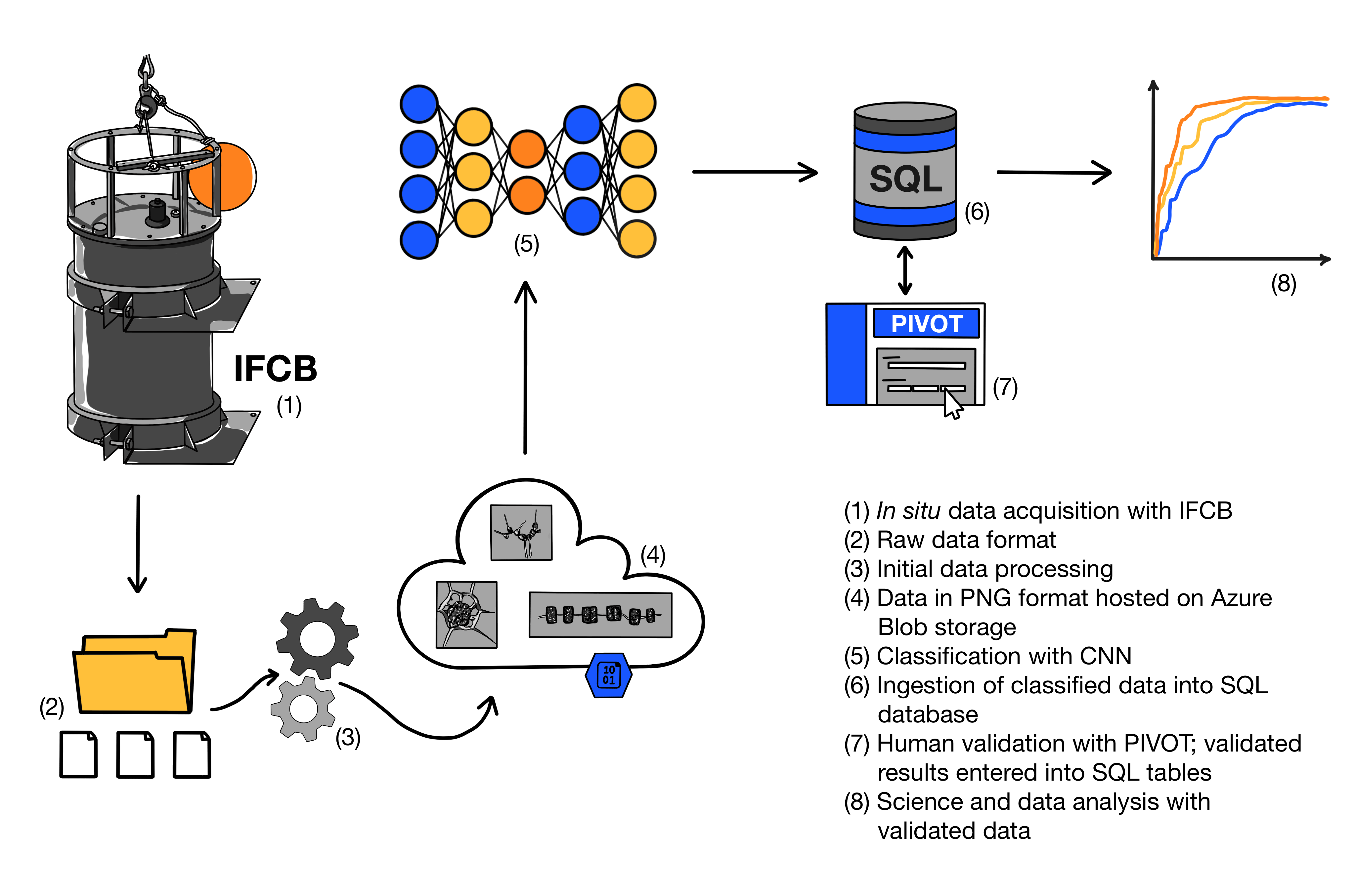
Notebooks
create_dataset_csv.py: Classifies all images in themlfolder that is created when converting raw IFCB data to png files with the CNN and produces a dataframe for analysis. Can be used with a folder of images stored locally or on the Azure blob.pivot_sql_setup.py: Runs all the necessary setup steps to create PIVOT and ingest the first set of data. Requires Azure blob storage and an Azure SQL database. This notebook also has the capability to add a new dataset to a pre-existing PIVOT SQL database.make_seabass.py: Takes in metadata and the dataframe of classified labels and produces a folder of SeaBASS-formatted files that can be submitted to NASA.
Other Files
environment.yaml: The file used to set up the ifcb-utopia Python environment. It contains all the packages needed to run the data-pipeline notebooks and PIVOT.global_val_setup.py: A file containing template dictionaries for cloud tool configuration information and investigator names, organizations, and contact information. It also has a calibration ratio variable that can be edited from the default 2.7488 pixels/micrometer. This information needs to be added before running the notebooks.
Marimo
I have chosen to use Marimo notebooks for this data pipeline. Marimo is an open-source, reactive Python notebook that can be run in notebook format, as a script, or as an app. Check out the Marimo website for more information: https://marimo.io/.
Setup Steps
data-pipeline repository
- Clone this repository to your local machine (instructions here).
Create a new python environment
Mac/Linux
- Use anaconda or miniconda to set up a new python environment.
- In your prompt, navigate to the folder containing this repo’s
environment.yamlfile. - Type
conda env create -f environment.yamland wait for the prompt to finish setting up the environment. It may take a while. - The environment’s name is “ifcb-utopia”, so activate it with
conda activate ifcb-utopia.
Windows
- Use anaconda or miniconda to set up a new python environment.
- Open this repo’s
environment.yamlfile in a text editor. - Comment out the tensorflow and utopia-pipeline-tools lines by typing # at the start of the line.
- In your prompt, navigate to the folder containing this
environment.yamlfile. - Type
conda env create -f environment.yamland wait for the prompt to finish setting up the environment. It may take a while. - Activate the environment with
conda activate ifcb-utopia. - Install tensorflow with
pip install tensorflow==2.13.1. - Install utopia-pipeline-tools with
pip install utopia-pipeline-tools.
Update your global values
- Open
global_val_setup.pyand input your configuration information in theconfig_infodictionary and investigator information indefault_investigators. - If you want to use the Azure blob, make sure you include values for
"blob_storage_name"and"connection_string"(e.g."blob_storage_name": "ifcbblob"). - To connect to an Azure SQL server and database, enter values for
"server","database","db_user"(username), and"db_password". - The CNN notebook can call a local or cloud keras model. Include values for
"subscription_id","resource_group","workspace_name","experiment_name","api_key","model_name","endpoint_name", and"deployment_name"if you want to use a cloud model. - SeaBASS files require information about the researchers involved in the project. Add names, organizations, and emails to the
default_investigatorsdictionary with the format:"Firstname_Lastname": ["Organization", "email@org.com"]for each individual.
Troubleshooting
- Make sure your pip is up to date (
pip install --upgrade pip) - If all else fails, you can brute-force create a new environment and individually install each package (this is not the best method, but it does allow for more modular troubleshooting).
- Contact the utopia-pipeline-tools owner if its setup requirements are making your computer freak out.
Getting updates
- Sync any repository (notebook) updates to your local machine with
git pull. - Get the latest version of utopia-pipeline-tools by activating the ifcb-utopia environment then typing
pip install --upgrade utopia-pipeline-tools.
Running the notebooks
This pipeline uses marimo notebooks. Open the notebook interface in the activated environment by typing marimo edit.